People
"The fact that current systems don't work well is a major motivation," says Alexander Polok, who won the Joseph Fourier Prize

This year’s second-place winner of the Joseph Fourier Prize is Alexander Polok, a Ph.D. student at FIT VUT from the Department of Computer Graphics and Multimedia. Polok, who also won the special IT4Innovations award in the competition for doctoral students in computer science and informatics, is a very promising young researcher. He has already achieved significant international success, having completed several study abroad stints and research projects. His research interests lie in the field of speech and language technologies. In this dynamic field, he was primarily drawn to automatic speech recognition in challenging conditions—whether due to reverberation, colloquial language, or multi-speaker conversations (e.g., during meetings), where voices also overlap. This is an area where experts face a number of challenges, as Polok noted during our interview.
Alexander Polok began his doctoral work on conversational systems (voicebots). It was there that he realized a fundamental problem that he continues to address in his research to this day: In a classic modular design, the conversion of speech to text results in loss of information contained in the original utterance (e.g., tone, emotion, and context). These systems often fail when broader context or paralinguistic information needs to be utilized. Polok therefore investigated how to integrate speech recognition and language modeling in a way that prevents these losses. Instead of the standard “speech → text → large language model” chain, he takes a different approach. “In order to perform tasks such as summarizing a message or answering questions in addition to ASR—that is, speech-to-text transcription—we have two options: Either we can transcribe the text and then assign the task, such as summarization, to the LLM. Or we can use hidden representations (numeric sequences that can also encode, for example, tone and emotions in speech), which are transformed to match the language model’s representations. This is done with the help of adapters, which can be thought of as small neural networks that convert the speech model’s output into a form the language model can process,” Polok explains. “Or you can also imagine it this way: you ‘merge’ all three models—that is, the neural networks—together. When you then add transformation blocks to this, we ensure that a single model can be deployed for the entire speech-to-speech process. And we prevent the loss of semantic information or emotions in the original utterance,” Polok bravely tackles the request for the most basic description possible of the fundamental motivation behind his work.
Over time, Alexander Polok began to focus on multi-speaker conversations and their transcription. “I’m currently working with data from situations involving 2 to 8, or even more, speakers. A characteristic of these situations is overlap—that is, a state where the utterances of several speakers overlap—which can account for as much as 80% of all communication. And the key point is that even the best speech and language-speech models fail when processing such situations. Two years ago, I proposed a method that could contribute to a solution, and I’m continuing to expand on it,” says Polok, commenting on his current major research topic.
From Therapy Recordings to Dixtral
How did Alexander Polok get into the field of speech technologies in the first place? “While studying at FIT, you encounter a number of research groups. One of the most successful is the speech researchers, Speech@FIT. That, of course, motivated me to start collaborating with them. At first, I worked with Pavel Matějka on the DeePsy tool, which is used to transcribe therapy sessions—that is, situations involving two speakers. Specifically, I focused on diarization—distinguishing who is speaking when—and then on ASR tailored specifically for Czech.” His work on DeePsy was the subject of Poloka’s bachelor’s and master’s theses, and this research motivated him to pursue a Ph.D. In the summer of 2023, he participated in the JSALT research workshop in Le Mans, France, where he was already working on model fusion during ASR—that is, situations where human speech processing utilizes hidden representations and does not involve a pure transcription of speech into text. “Then I joined the CHiME research competition, which for more than 10 years has focused on speech processing in challenging conditions—such as a room with a single microphone capturing speech from multiple speakers,” Polok says, describing the next step in his academic journey. The solution he proposed for CHiME became the foundation for the key result of his work: the Dixtral tool.
Dixtral, on which Polok collaborated with researchers from FIT and Carnegie Mellon University (and which builds on his earlier collaboration with Johns Hopkins University), combines two functionalities: Polok’s earlier tool, DiCoW, which can isolate a specific speaker’s speech using diarization information (data indicating the time intervals during which the speaker spoke); and the Voxtral audio AI model (from the French company Mistral AI), which can perform tasks such as summarization and answering questions. Dixtral can therefore process recordings featuring multiple speakers, distinguish between their speech, and generate transcripts, summaries, or answers to questions based on the selected speaker’s remarks. Its main advantage is that it combines diarization (identifying speakers and when they speak) with understanding of spoken content in a single system, allowing it to better handle complex conversations and overlapping speech. Furthermore, it is capable of processing longer recordings than is typically the case. “I recently had an article accepted for this year’s Interspeech conference, which focuses precisely on this tool’s ability to summarize utterances, identify key topics, or answer questions posed about speakers’ remarks,” says Polok, describing Dixtral’s versatility. “Dixtral also does not require enrollment—that is, a short initial recording that is entered into the database and used to identify the speaker in real time during utterances,” Polok emphasizes as another advantage of his solution. Enrollment has several weaknesses: It must be available in advance, and it is a short recording made under different acoustic conditions, which limits the accuracy of subsequent identification. “Dixtral only needs partial, local information to work; it doesn’t need a global picture, nor does it need the speaker’s identity. It then works across different languages and environments,” Polok concludes his description of how the tool works.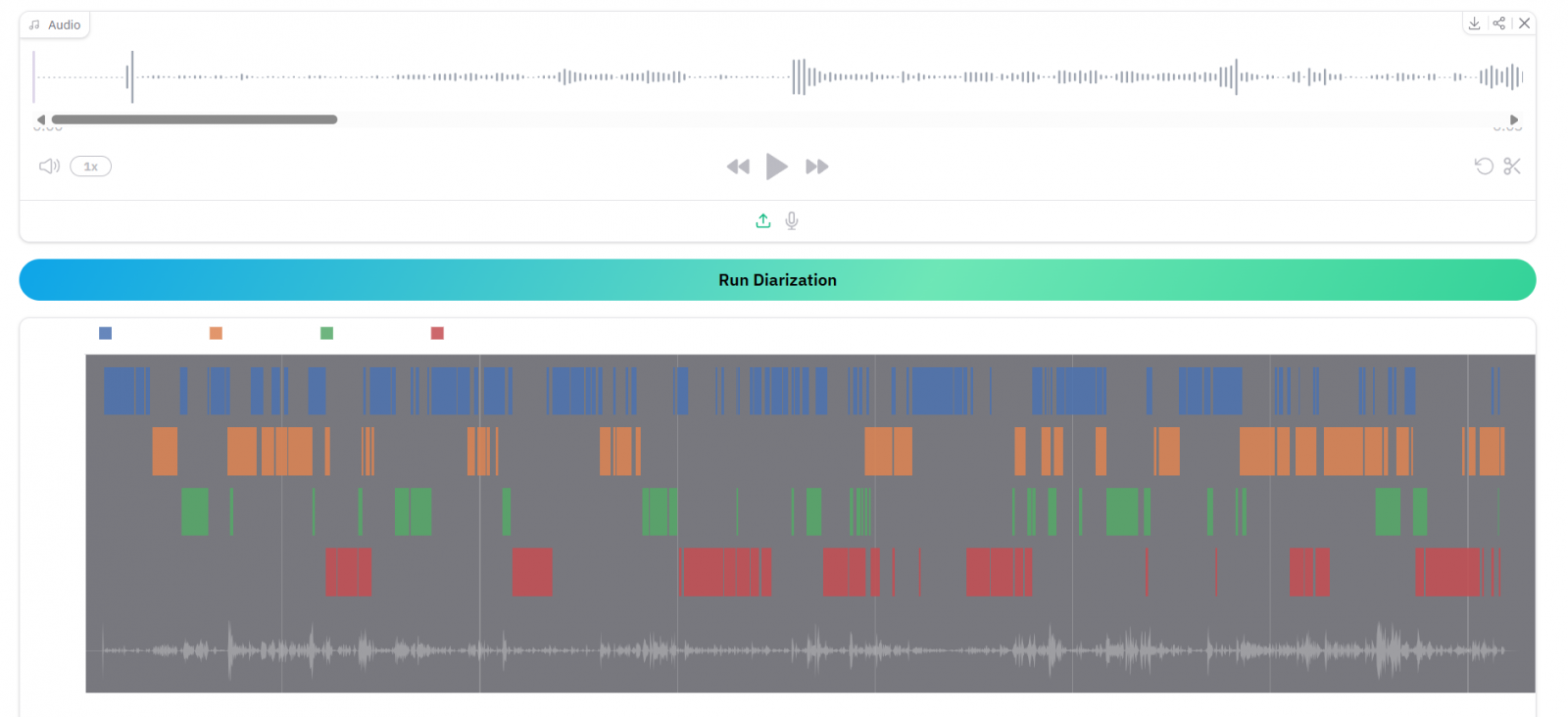
The Future? A Lot of Work Ahead
Polok’s solutions are now inspiring giants like Nvidia and NTT. Why did he become interested in processing multi-speaker situations in the first place? “Probably because existing solutions don’t work well enough,” he says with a smile. “Of course, I’d like to eventually reach a point where multi-speaker ASR systems have the same error rate as those for single speakers. Current systems have error rates in the tens of percent. The research has potential for the next ten to twenty years,” Polok comments on the possible future. He also mentions other challenges: situations where the speaker doesn’t change, but the language of speech does. “My dream is to focus on research that ordinary people use every day. For example, for processing meetings. For what we’ve achieved so far, I have to thank the research group, Honza Černocký, and Lukáš Burget. I really have nothing to complain about,” concludes Alexander Polok with a smile, the recipient of second place in this year’s Joseph Fourier Prize.
It should be added that Alexander’s solution has the potential to become an important implementation tool within the CZAI Factory project, in which several Brno “speech engineers” are involved and about which we last wrote in May in connection with its official launch.
Source: FIT BUT
FactDeMice Project: AI as Tool for Journalists and Businesses, Not Arbiter of Truth
In research, on has to keep learning. It's a great job for curious people, says graduate working in Singapore
Doctoral students in engineering study the behaviour of the circulatory system. Neural networks also help them
FIT scientists want to prevent pilots from being blinded by lasers. They are developing a security system that will find the attacker
Trucks and buses will be equipped with nanoradars and sensors, experts from FIT BUT participated in their development. It will increase road safety